
Everyone is Launching AI Agents. What's Being Deployed?
A deep dive on the next cycle of biopharma's AI buildout


Last year's "growing buzz around AI agents" that we surveyed has since grown into a full avalanche of infrastructure commitments, partnerships, and agent launches across nearly every corner of biopharma. Let's take a fresh look.
A team at Stanford recently posted a preprint describing a system they called “Virtual Biotech”: a coordinated squad of AI agents organized to mirror a real drug discovery company, complete with a virtual Chief Scientific Officer, specialized scientist agents, and over 100 tools for querying biomedical databases.
For their headline demonstration, they deployed over 37,000 agents in parallel, each one tasked with annotating a single clinical trial, linking therapeutic targets to genomic and single-cell transcriptomic features. The resulting dataset spans 55,984 trials. The analysis turned up what the authors call previously unreported associations: drugs targeting cell-type-specific genes were 40% more likely to advance from Phase I to Phase II, 48% more likely to reach market, and showed 32% lower adverse event rates.
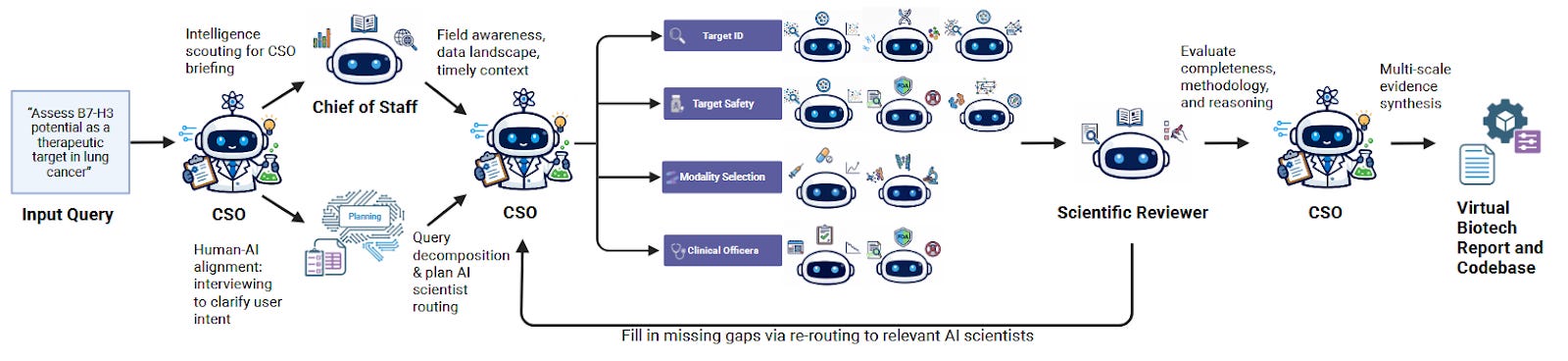
In another case study, the system pulled together genetics, transcriptomics, and clinical data on B7-H3 in lung cancer and landed on an antibody-drug conjugate strategy, the same bet several pharma companies are already running in the clinic. It also flagged liabilities and differentiation angles. The whole thing reportedly cost $46 in API credits and took less than a day.
The Virtual Biotech is one lab’s preprint, but it lands in what we recently likened to a “gold rush”—agents are being deployed across clinical operations, translational biology, antibody design, and regulatory workflows. Major pharma companies are in an apparent compute arms race, stacking GPU clusters and billion-dollar AI partnerships within months of each other. Startups backed by hundreds of millions are launching agent-focused platforms. NVIDIA’s Jensen Huang even went so far as to declare agentic AI “the new computer” at this year’s GTC.
Whether the implementations match is another question. In a recent experiment, researcher Liang Chang asked—”Can AI make better decisions than pharma executives?” and sent AI agent teams back to a pivotal 2012 decision in oncology, the BMS vs. Merck biomarker strategy that ultimately decided the Keytruda-Opdivo war, and found that both Claude and GPT independently recommended the same path BMS took. The path that lost.
The agents produced rigorous analysis, identified the exact competitive threat, and still followed the consensus. As Chang put it: “AI can give you the best possible analysis. It can’t give you the courage to go against it.”
What can AI agents do today, where are they falling short, and why is everyone building them?
🤖 Why agents, and why now?
A historical detour. The term “agent” gets used loosely enough in AI marketing that it might be worth tracing from its original meaning. The ideas behind it were actually tested long before today’s language model AI existed. The fundamental idea behind an agent is a feedback loop where a system perceives its environment, observes changes and adjusts in response.
Norbert Wiener and W. Ross Ashby worked on this in the 1940s, doing cybernetics. Their framework kept coming back to one idea that effective control depends more on the quality of the feedback loop than on the sophistication of the controller. Even a simple device like a thermostat qualifies: it doesn’t need to be smart, it needs a clean reading and a reliable switch.

For roughly three decades after that, the dominant AI paradigm assumed the opposite: that intelligence requires building an internal symbolic model of the world and then reasoning over it. Sense the environment, build a representation, plan against it, act. This was sometimes called GOFAI (“Good Old-Fashioned AI,” John Haugeland in 1985), and it produced systems that could play chess and prove theorems but later couldn’t walk across a room without tripping.
By the late 1980s, Rodney Brooks at MIT was building robots that dispensed with internal world models entirely. These had layered behaviours (avoid obstacle, follow wall, seek light) that composed into complex action without any central planner.
His argument against the symbolic AI mainstream was that intelligence doesn’t live inside the agent. It comes from the agent’s relationship with the environment. In “Elephants Don’t Play Chess” (1990), he wrote:
The world is its own best model—always exactly up to date and complete in every detail.
A simple agent in a well-structured environment beats a complex one in a poorly structured one.
Through the 1990s, multi-agent systems became a formal subfield concerned with how to coordinate many autonomous software agents, each with limited capabilities, so that useful collective behaviour emerges. The Belief-Desire-Intention models taken from philosophy and applied to software gave individual agents beliefs about the world, desires they wanted to achieve, and intentions they committed to. Swarm algorithms showed that coordination could arise without any agent understanding the whole and air traffic simulations demonstrated the approach at scale.
When returning our attention to the modern day version of LLM-based AI, let’s remind ourselves that, at its core, a large language model predicts text. Fittingly enough, it got good at this through human feedback during training.
And here is where the circle closes. We spent decades scaling the internal capability of AI systems, built the largest, most capable text-prediction machines in history, and the moment we try to make them do things in the world, act on observations, use tools, adjust to what happens next—the oldest insight in the field loops right back on us. To make an LLM good at acting (and, perhaps, closer to intelligence), we are back to feedback loops.
💭 Agents today
The current, fashionable incarnation of this idea is an LLM with access to tools.
Instead of a chatbot that answers questions, an agentic system acts. It breaks a goal into subtasks, calls external tools at each step (e.g. databases, APIs, code execution environments, other agents), and, ideally, carries context across the chain without losing the thread.
In biotech and pharma, this can map onto things like target identification, literature mining, data extraction, safety profiling, trial design, and regulatory documentation, all run through separate teams, separate tools, and separate institutional memories. An agentic system can serve as connective tissue across these, operating at a speed and parallelism higher than any single team.
Why now? A few reasons behind the current momentum:
Context windows grew large enough that models can now hold meaningful complexity in a single reasoning chain.
Tool-use capabilities matured: previously, every agent needed custom connectors to every data source, which has now moved closer to plug-and-play.
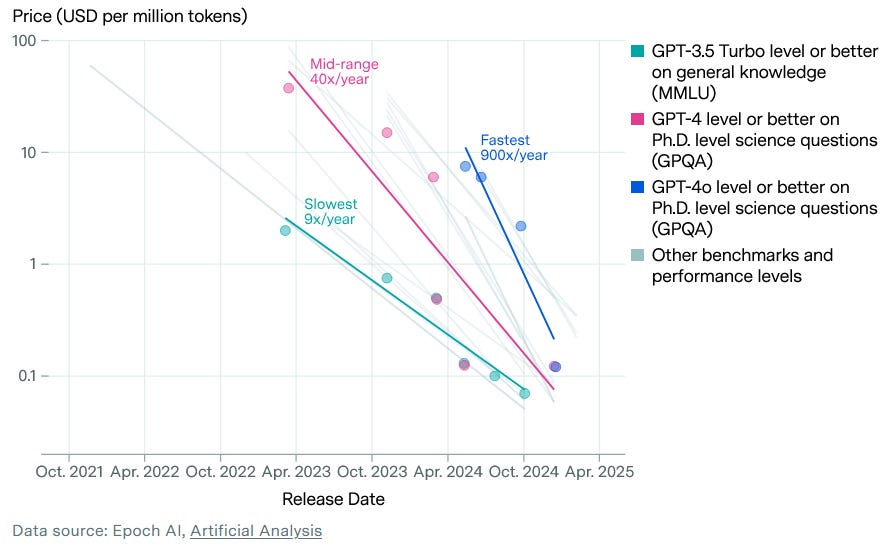
Inference cost dropped. According to Epoch AI, the price of achieving a given level of model performance has been falling by 10x to 900x per year, depending on the benchmark. GPT-4-level performance that cost $20 per million tokens in late 2022 now runs at roughly $0.40.
Open-source agent ecosystem exploded. From orchestration frameworks like LangChain, CrewAI, and AutoGen to full personal-agent runtimes like OpenClaw, the barrier to building an agentic system dropped considerably. In many cases, there’s no need to wire everything from scratch.
As a timely demonstration from pure machine learning recesses, the other day, Andrej Karpathy (former head of AI at Tesla and one of the original OpenAI researchers) open-sourced a minimal setup where an AI agent modifies code, runs a five-minute ML experiment, checks if the result improved, keeps or discards, and loops. Running on a single GPU node (that’s still a lot of compute), he left it iterating for two days and came back to ~20 improvements that all held up.
Karpathy called it ‘wild’ as he’d spent two decades doing exactly this kind of iterative neural-net tuning manually, and his very first naive attempt with the agent already beat what he considered a well-tuned project. His read on where it leads is that every frontier lab will do this, spinning up agent swarms that collaborate to tune models at increasing scale and “...humans (optionally) contribute on the edges.”
⏪ Last we checked
When we surveyed the landscape of AI agents in biotech last spring, the honest summary was this:
Early-stage, fragile, mostly academic.
A handful of systems had demonstrated interesting capabilities like TxAgent (Harvard), BioDiscoveryAgent (Stanford), SpatialAgent (Genentech), and Causaly’s knowledge graph agents.
None were in production, tool chains were brittle, costs were steep, and there was no regulatory framework for any of it.
The field was caught between two realities of impressive demos on one side, and on the other, as always, the irreducible complexity of biology. But things changed quite fast.

⏳️ What changed?
The most visible change is what’s happening with the hardware and the scale of investment, starting with infrastructure.
🔹 Eli Lilly went live with LillyPod in late February with over 1,000 GPUs delivering 9,000+ petaflops. That followed a $1 billion co-innovation lab with NVIDIA announced in January. Through Lilly’s TuneLab platform (with access to models trained on ~$1B Worth of proprietary drug discovery data), select models will be available to biotech partners via federated learning where partners train on Lilly’s models with their own data, without transferring it.
🔹 Going even higher on compute, Roche just announced the deployment of over 3,500 GPUs across the U.S. and Europe, the largest announced GPU footprint in pharma. Genentech’s Aviv Regev framed it around Roche’s “Lab-in-the-Loop” strategy, which she said they have pursued for more than five years. An NVIDIA pre-briefing offered some early concrete numbers: nearly 90% of eligible small molecule programs at Genentech now integrate AI, and at least one molecule was designed measurably faster.
🔹 Extending into the instrument layer, Thermo Fisher and NVIDIA announced a strategic collaboration at start of this year to develop AI-native laboratory workflows and instrumentation.
But the hardware is ahead of the results. Lilly’s Diogo Rau told CNBC last October that AI-assisted benefits would likely materialize around 2030. At the LillyPod inauguration, he was cautious: “The hype is actually a serious threat to the research itself. Because if the hype becomes the story, then we’re all going to be disappointed.” The infrastructure is there, but the public record still contains far more detail on compute scale than on named downstream outputs. Roche has described at least one molecule whose redesign was accelerated.
That’s the infrastructure investment. What about actual use?
Pharma appears to see the first value of agentic AI in fixing data and workflow mess, not in autonomous discovery:
In the Owkin/STAT survey, 37% called implementation “very important,” but only 3% said it was the number one priority. More importantly, respondents put data challenges first at 41.6%, ahead of early discovery at 28.7%.
Deloitte‘s September 2025 survey of 100 U.S. healthcare technology executives found a similar pattern from the budget side: 61% were already building agentic AI initiatives or had secured funding, and 85% planned to increase investment over the next two to three years.
The Microsoft-NEJM AI report, focused on health systems, found actual deployment even thinner—just 3% of 30 surveyed organizations, with 43% still in pilots.
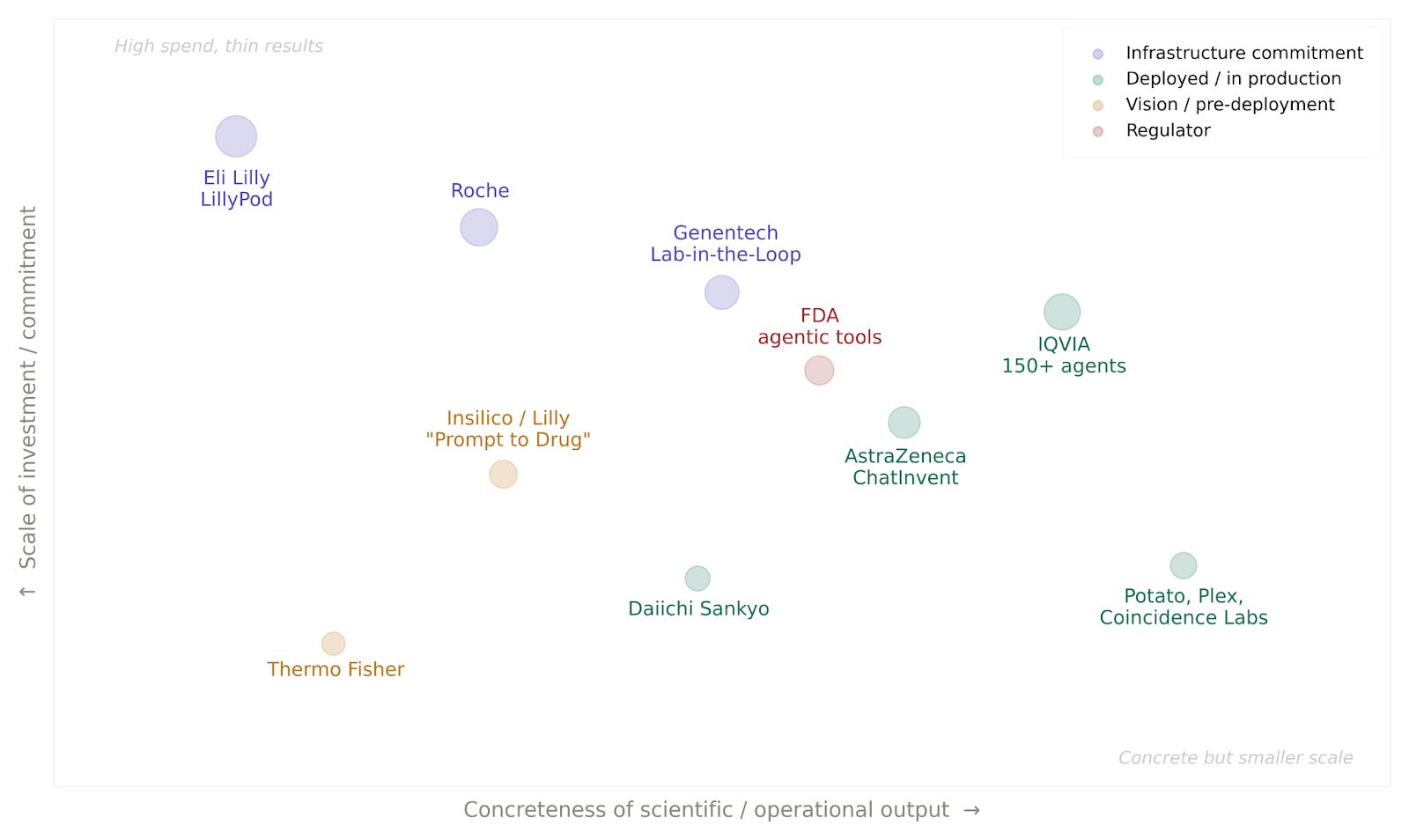
The numbers above show that deployment is thin, but there are already a few visible examples.
➕ AstraZeneca
AstraZeneca published one of the first honest accounts of putting an agentic system into a real pharma pipeline. Their paper describes ChatInvent, a conversational interface for drug discovery that evolved from a single-agent proof of concept into a multi-agent architecture. The paper is notable for what it says about how things break: every LLM upgrade required at least a week of prompt re-tuning and could change agent behavior unpredictably. The supervisor agent would silently mangle inputs, sub-agents would sometimes refuse tasks they were perfectly capable of handling. The multi-agent system was faster and cheaper than the single-agent one, although it also introduced more errors.
➕ IQVIA
At GTC 2026, IQVIA launched a unified agentic platform built with NVIDIA that bundles over 150 specialized agents for clinical, commercial, and real-world evidence workflows. The collaboration with NVIDIA dates back over a year; one of the earlier agents, a clinical data review orchestrator first shown at GTC Paris in mid-2025, uses automated checks and sub-agents to catch data issues early, cutting the review cycle from seven weeks to two. The initial release covers trial start-up, target identification, data review, market landscaping, and field sales preparation, with more agents expected in Q4.
➕ Daiichi Sankyo
Daiichi Sankyo has been using AI built with BCG to personalize responses to patient and HCP queries inside its Veeva-based systems across Europe and Canada. It's a more commercial deployment than AstraZeneca's experiment or IQVIA's agents, with content generation and protocol writing on the roadmap for 2026.
➕ Visions, and Others
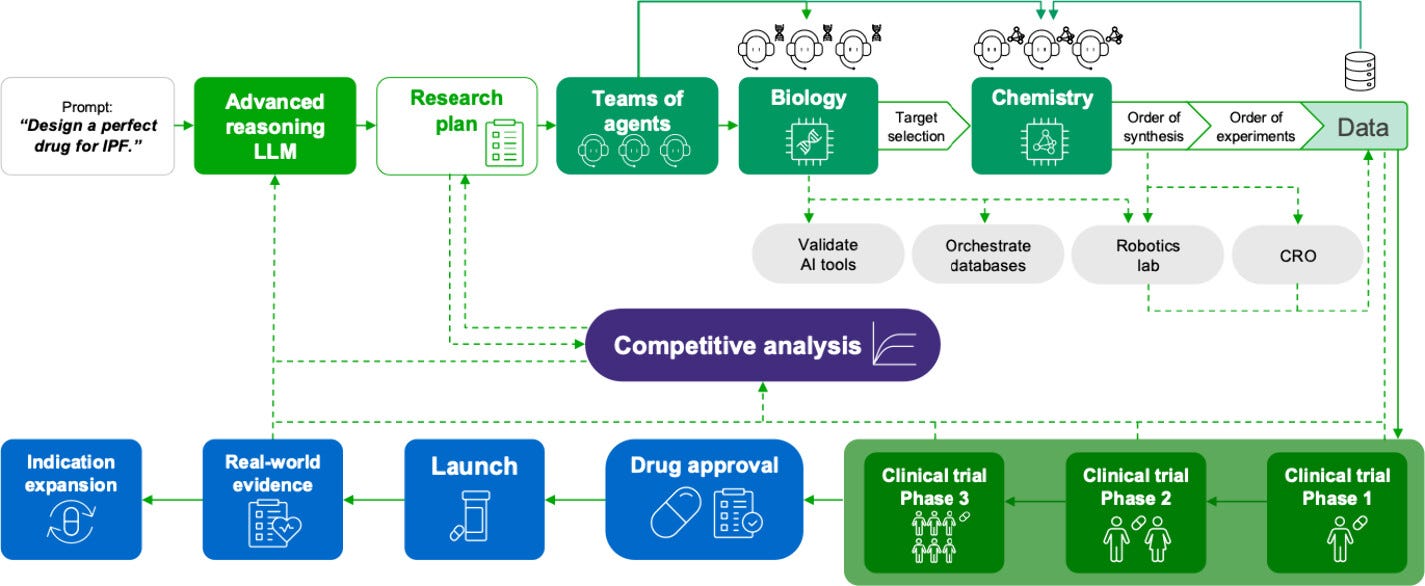
There’s recent Insilico Medicine and Eli Lilly paper worth flagging that belongs in a more of a ‘vision’ category for now. Their February “From Prompt to Drug” paper describes a fully autonomous pipeline where a central reasoning controller coordinates specialized AI agents across target discovery, generative chemistry, automated synthesis, and clinical planning in a single closed-loop workflow. A scientist types a prompt; the system orchestrates the rest. The authors acknowledge the end-to-end vision “may seem far beyond what is possible today,” and argue the individual building blocks already work at a smaller scale.
➕ And then, there’s the FDA
The FDA also deployed agentic AI capabilities for its own staff in December 2025, though the rollout has been bumpy. The agency’s earlier gen AI tool, Elsa, was seen fabricating nonexistent studies and misrepresenting research, with employees describing it as unreliable for anything beyond meeting notes. All of this against the backdrop of over 1,000 staff cut from the drug review center and multiple missed approval deadlines. The regulator is experimenting with the same tools it will eventually have to regulate, and running into the same problems.
📝 A recent review in Drug Discovery Today suggests agentic AI is already valuable in drug discovery, just not where most of the headlines are pointing.
The paper covers eight case studies from companies including Potato, Plex Research, and Coincidence Labs, several with specific quantitative benchmarks. The gains that hold up are in the operational middle of discovery: literature synthesis, protocol generation, assay design. Potato’s Tater agent took the design cycle for a qPCR assay from one-to-four months down to under two hours, although empirical validation was still needed.
The agent architectures in these systems mirror how discovery teams already work— supervisor delegates to specialists, shared context, iterative refinement—just without the multiweek meeting cadence. The authors note that current benchmarks capture whether an agent got the right answer but not whether the reasoning behind it was sound, and that early-stage results like cell-level inhibition don’t guarantee downstream translation.
One gap: every case study reports time savings, none report what the infrastructure costs to build and run. But the broader view is that the real value right now is compression of the coordination overhead between steps that already work on their own, not autonomous science.
📌 What does this add up to?
The infrastructure is real, the investment is committed, and a handful of systems are actually running in production workflows. But the gap between the hardware announcements and the named scientific outputs is still wide, and the honest accounts show that multi-agent systems in messy real-world pipelines are notoriously fragile. The most grounded read right now is that agentic AI in biopharma is just right on cusp of leaving the “interesting demos” phase but well short of the “reliable infrastructure” phase.
🧪 Agents doing science
A single LLM asked to check its own work tends to agree with itself. In one medical study, some frontier models (in 2025) complied with illogical requests up to 100% of the time. Most multi-agent systems built over the past year have had to engineer around this. The solutions vary, but they all converge on the same idea of creating friction.
Google‘s AI co-scientist uses what it calls a “generate, debate, and evolve” framework where agents propose hypotheses, other agents critique them, and the survivors get refined through iteration. In a collaboration with Stanford, two of three co-scientist-recommended drugs for liver fibrosis showed “significant anti-fibrotic activity” in human liver organoids.
DeepMind‘s Aletheia has a generator-verifier-reviser loop where agents produce solutions, check them for flaws, and correct or discard faulty reasoning.
Stanford‘s Virtual Biotech (the one we opened with) assigns a dedicated reviewer agent that evaluates outputs and pushes back. The same lab is also trying out the opposite approach with a generalist single Biomni agent that skips the team structure entirely, composing its own workflows across 25 biomedical subfields.
FutureHouse, an Eric Schmidt-backed nonprofit in San Francisco building what it calls an “AI Scientist,” went wider: a single up-to-12-hour run executes up to 42,000 lines of code across 166 data-analysis agent rollouts and reads roughly 1,500 papers across 36 literature-review agent rollouts, coordinated through a structured world model. It reported seven discoveries, four of them “novel,” and three that independently reproduced unpublished human findings.
Even though friction helps, it doesn’t solve the problem entirely. Just from the systems above: Kosmos’s reports were rated about 79% accurate by independent scientists, but FutureHouse’s own team notes the system often chases statistically significant but scientifically irrelevant findings. Aletheia ran through all 700 open Erdős problems in a week, its verifier flagged 212 as potentially correct, human experts confirmed 63 as technically valid, but only 4 resolved genuinely open questions. Sakana AI, about a year ago, produced what it called the first fully AI-generated paper to pass peer review, but the caveat here is that it was a workshop submission, humans selected which generated papers to submit, and the paper was withdrawn.
Model providers are, of course, ambitious and optimistic.
🔹 OpenAI told MIT Technology Review that building a fully automated AI researcher is now its explicit priority with an “autonomous research intern” by September, a full multi-agent system by 2028. Its chief scientist Jakub Pachocki described a future where a “whole research lab” exists inside a data center. Doug Downey at the Allen Institute for AI calls the prospect “exciting” but cautions that multi-step scientific work compounds error, and chaining tasks makes success less likely across the whole sequence.
🔹 Anthropic is focusing less on a standalone autonomous researcher and more on embedding Claude into existing scientific workflows through partners like HHMI’s Janelia campus and the Allen Institute, while extending into research infrastructure and biopharma R&D through its Claude for Life Sciences rollout.
So while some push toward replacing the process entirely, others look to situate the tools inside an already existing human/institutional process.
Continuing with limitations—when agents are all instantiations of the same underlying model (or similar models), their “disagreement” is bounded by shared priors, shared training data, and shared failure modes. They’re unlikely to catch each other’s systematic blind spots, and only catch surface-level inconsistencies—a so-called ‘tyranny of the majority’ where homogeneous agents converge on shared errors unwittingly. None of them can encounter surprise.
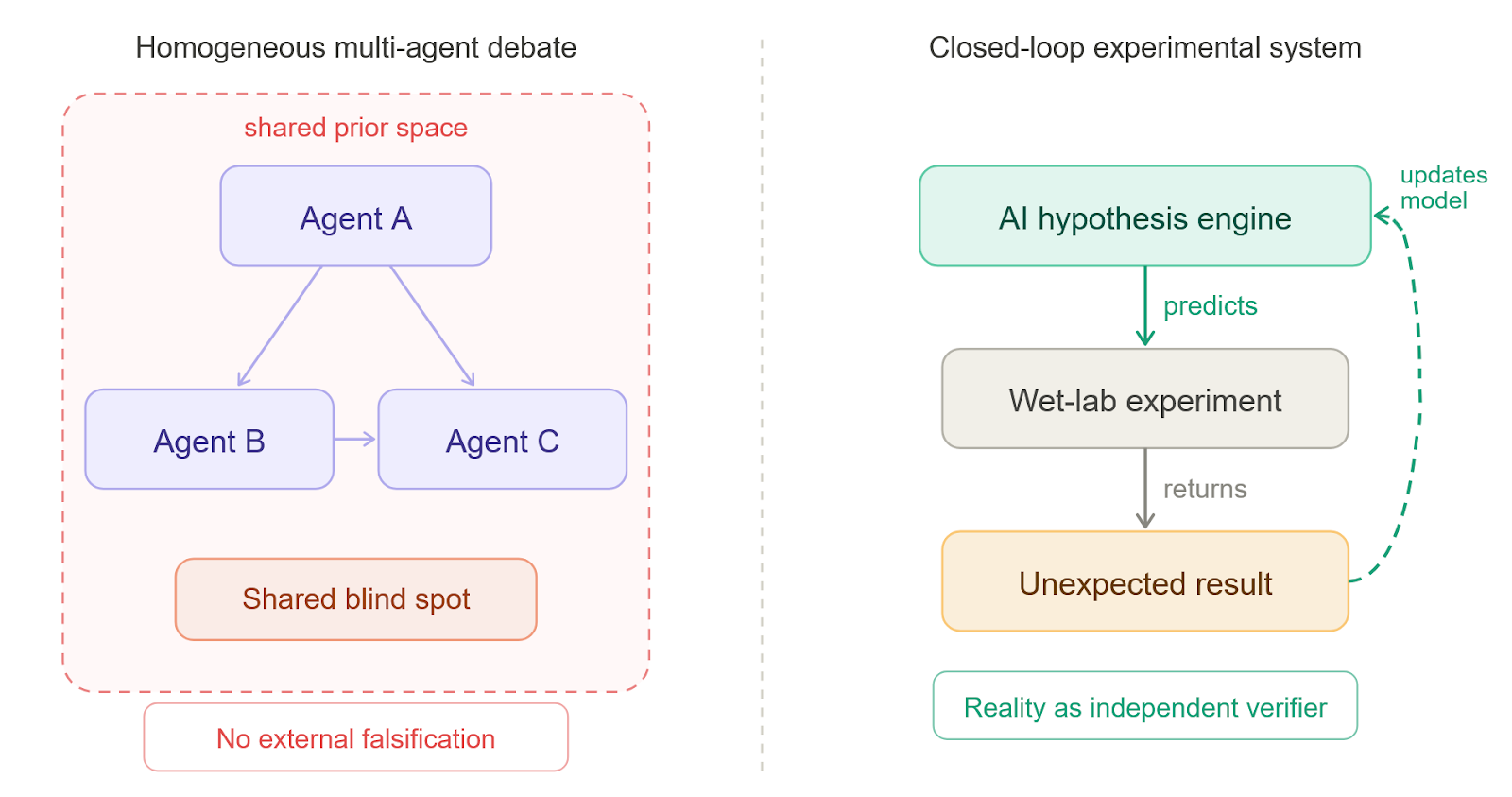
A real experiment can falsify a hypothesis in a way no agent in the loop anticipated. Multi-agent critique can’t replicate that. Conveniently, a real science lab provides that ‘for free’, as some friction with reality is inherent to it.
♻️ The lab-in-the-loop
Let’s recall Rodney Brooks when he wrote that “the world is its own best model.” A wet lab isn’t quite the world, but it’s a lot closer to it than AI agents debating themselves virtually. Ross King‘s Robot Scientist ‘Adam’ was already doing something close to this in 2009 by formulating hypotheses, running physical experiments, interpreting results, and confirming novel gene functions in yeast without a human in the loop.

Lila Sciences’ CTO Andrew Beam frames a certain bottleneck we’ve now reached: AI advanced fastest in domains where results are “easy to verify,” like mathematics, where proofs can be checked mechanically. Science doesn’t offer that shortcut, so verification means running an experiment. Beam posits that boosting the throughput of experiments describing the physical world will provide the critical data stream for the next generation of AI models.
The approach works best when three conditions align: a large combinatorial space, automatable chemistry, and a fast quantitative readout.
A decent example of this is LUMI-lab—a self-driving platform for ionizable lipid discovery recently published in Cell. A foundation model pretrained on 28 million molecular structures proposes candidates, robots synthesize and test them, and the results feed back in. One design-make-test-learn cycle every 39 hours. Over ten rounds, the system evaluated over 1,700 lipids, and by round ten more than half exceeded the transfection efficiency of MC3, a clinical-grade benchmark. The top compound achieved 20.3% gene editing in mouse lung epithelial cells via inhalation, reported as a new bar for inhaled CRISPR delivery. Humans still handle hardware errors and interpret edge cases, but the experimental loop itself runs unattended.
Not every lab-in-the-loop system aims for full autonomy: Le Cong’s (Stanford) and Mengdi Wang‘s (Princeton) LabOS keeps the researcher in the loop and augments them instead—AI agents connected via smart glasses and robots read experimental context and assist in real time, extending their earlier CRISPR-GPT work into the physical lab.
Ginkgo Bioworks and OpenAI report they connected GPT-5 to Ginkgo’s cloud laboratory and optimized cell-free protein synthesis across six iterative rounds over six months, testing over 36,000 reaction compositions. They say the system reduced production cost by 40% relative to prior benchmarks. One important caveat is that the results were demonstrated on a single protein (sfGFP), and when tested on twelve additional proteins, only half were even detectable. Ginkgo is already selling the AI-improved reagent mix commercially.
Roche’s “Lab-in-the-Loop” strategy, Lilly’s integration of agentic AI with robotic biomanufacturing, and Lila Sciences’ autonomous labs are all aimed at this kind of continuous computation-experiment cycle. The barrier to entry is also dropping because cloud lab platforms like Strateos and Emerald Cloud Lab let smaller teams plug into robotic infrastructure without building their own.
📌 Reality checkpoint
The gap between what these systems can do and what they’re being described as doing is still wide. The idea of lab-in-the-loop is more trustworthy than pure virtual debate, but it only works when the problem is shaped right. Most biology either isn’t shaped right or is hard to shape. The more durable near-term bet is probably the less glamorous one: embedding these tools inside existing scientific institutions rather than replacing the process completely, accepting that human judgment stays load-bearing for now, and letting the autonomy expand incrementally as reliability earns it.
⛓️💥 What doesn’t work
Now, back to limitations.
Reliability. A February 2026 paper from Princeton and Cornell evaluated 14 agentic models and found that nearly two years of rapid capability gains have produced only modest improvements in reliability. Agents that can solve a task often fail on repeated attempts under identical conditions, with outcome consistency scores ranging from 30% to 75%. All three major providers clustered together. Scaling up didn’t uniformly help: larger models improved calibration and robustness but actually hurt consistency, showing more run-to-run variability. An agent that passes a benchmark may behave differently each time you run it on the same input.
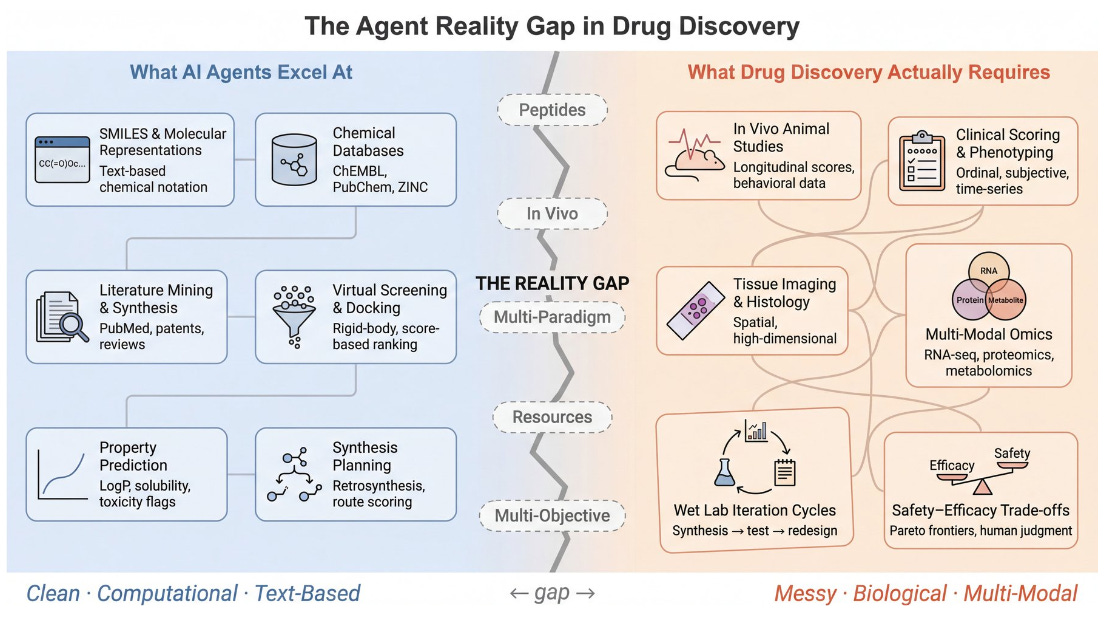
Architectural narrowness. A systematic evaluation of six drug discovery frameworks (Wijaya, Feb 2026) found all six locked into the same pattern: LLM reasons over text, calls APIs. That works for literature review and SMILES-based molecular design. It breaks when we need what drug discovery actually requires: model training, reinforcement learning, simulation, in vivo data integration, multi-objective optimization. The bottleneck isn’t really model knowledge (frontier LLMs reason about peptides competently) but the fact that no framework exposes those capabilities. There’s also a resource assumption baked in misaligned with small biotech realities: all six frameworks assume large-pharma data volumes, cluster-scale compute, and specialized teams.
Having several LLMs critique each other’s reasoning is the most discussed mitigation. The evidence is growing, and it’s mixed.
Estornell and Liu (NeurIPS 2024) formalized the core problem as “tyranny of the majority”: when most agents share a misconception, minority agents conform rather than push back. The echo chamber follows from models sharing training data, priors, and failure modes.
Wynn and Satija (2025) went further, showing that debate can actively degrade performance—models shifted from correct to incorrect answers by favoring agreement over challenging flawed reasoning, even when the stronger model outnumbered weaker ones.
Wu et al. (2025) confirmed the pattern from a different angle: in controlled experiments, intrinsic reasoning strength and group diversity drove debate success, while structural tweaks — depth, turn order, confidence reporting — did little. You cannot scaffold your way past weak reasoning.
Mixed-vendor teams help. Yuan et al. (Feb 2026) showed that assembling agents from different model families consistently outperformed single-vendor teams in clinical diagnosis, catching blind spots that homogeneous teams reinforced. But this is diversifying error profiles, not eliminating error.
📑 The echo chamber has an upstream version—Marinka Zitnik, associate professor of biomedical informatics at Harvard, noted in a recent Fay Lin’s GEN feature that 95% of all life sciences publications focus on roughly 5,000 of the most well-studied human genes. An agent trained on that literature will generate hypotheses that cluster around the same targets, not because the model lacks reasoning ability but because the knowledge base is lopsided.
Diversifying the model vendor doesn’t fix a skewed training signal. What does, at least partially, is tying agents to data modalities the literature underrepresents—single-cell sequencing, molecular structures, longitudinal clinical trajectories—which is another way of saying: back to the lab.
And there’s more:
Tool fragility. In AstraZeneca’s case, every LLM upgrade required at least a week of prompt re-tuning, supervisor agents mangled inputs, sub-agents refused tasks they could handle, and multi-agent setups introduced more errors than single-agent ones. A single unexpected API response crashes a multi-step chain. Recovery is ad hoc.
Error compounding. An agent that’s 95% accurate per step drops below 60% over a ten-step chain.
Preclinical speed is not total speed. AI compresses early discovery timelines. It does not compress clinical trials, patient enrollment, regulatory review, or biology itself.
Presently, agents are getting better at talking about science faster than they’re getting better at doing it.
🔒 What can go wrong
While ‘what doesn’t work’ is about epistemological and performance failures like reliability, narrowness, hallucination, echo chambers, regulatory gaps (failures in a benign environment)—there’s also ‘what can go wrong’ adversarial failure—what happens when someone is actively trying to break or exploit the agent?
Agents with access to clinical data, lab automation systems, and regulatory documents present an attack surface that we are only starting to reckon with. Cisco’s State of AI Security 2026 report found that only 29% of organizations felt prepared to secure agentic deployments.
Anthropic reported that in mid-September 2025 it detected what it described as the first documented large-scale cyberattack executed without substantial human intervention, targeting roughly thirty entities across sectors including finance and chemical manufacturing through manipulated Claude Code.
In pharma, where a compromised agent could alter experimental protocols, misroute regulatory filings, or leak proprietary compound data, the consequences are sector-specific and hard to bound. The now-(in)famous “move fast and break things” motto that somewhat works in consumer software carries a different risk profile here.
🔭 Looking ahead
The tools evolved, deployments are growing (if thin), and many are building their own or adding on agents. The AI infrastructure commitments are serious, and so is the gap between what’s been announced and what’s been shown to work. Somewhere between a gold rush and a correction there are a few things to look out for:
Regulation. This January, the FDA and EMA jointly identified ten principles for good AI practice across the medicines lifecycle, spanning work from early research through post-market activities. The EU AI Act’s high-risk provisions are now coming into force, with healthcare AI in scope. But neither touches agentic AI specifically. Autonomous agents that plan, chain tools, and act across multi-step workflows present a different challenge that the current frameworks haven’t caught up to.
First regulatory submission with agentic contributions. At some point, someone will file an IND where agents meaningfully contributed to the evidence package, target selection, data analysis, or safety profiling. When a regulator has to evaluate that and decide what counts as adequate documentation of what the agent did and why, there will be a conversation around audit and accountability.
Interoperability standards. Seed-funded by Genentech, The Pistoia Alliance is building agent-to-agent communication protocols for life sciences. Although most companies aren’t yet at the stage where cross-vendor agent communication is the binding constraint.
Talent. The scarcest resource in agentic AI deployment is people who combine AI engineering with life sciences domain knowledge and quality systems experience. Pistoia Alliance polls rank skills shortage as the second-biggest barrier to AI adoption in pharma, behind resistance to change. Many are trying to build these hybrid teams from scratch while simultaneously running pilots.
Consolidation & Stratification. The field is splitting between companies with proprietary biological data and those building on public data alone. This matters because data moats increasingly determine which AI/agent systems can produce differentiated outputs.
The field is moving fast enough that a survey like this one dates quickly. There is a lot of inflated optics surrounding AI, and the current cycle is agents—so in the crossfire of major forces and infrastructure investments, that’s worth keeping in mind when gauging the reality.
The underlying tension between what these systems can do and what biology actually requires will stay for a while. We’ll be watching for named partnerships and plans, of course, but more so (and mainly) for tangible outputs and reproducible results.
As always, if you're working on any of this or watching it from the inside—we'd love to hear what you're seeing, leave a comment!
I broadly agree with this. An important limitation, especially in biology, is that many problems can't be reduced to clean evaluation loops. When data is sparse and heterogeneous and hypotheses aren’t tied to a single metric, it can be unclear what the agent is even optimizing.
This makes fully AI-only agentic workflows fundamentally constrained. Even with multiple agents, you still get shared priors and failure modes as you point out.
To me, the more promising direction seems hybrid: workflows that incorporate AI alongside human judgment and mechanistic modeling. This does not just allow faster pattern recognition, but also representing and testing causal structure.
I wrote a short essay expanding on this if anyone’s interested.
Are you thinking about featuring agentic workflows like this in your article as a real-world application of how we map complex, higher-order structures in data?