
17 More Biomedical Foundation Models
MIT & Recursion's Boltz-2 just launched—here’s a quick scan of 15+ new models spanning chemistry, oncology, trials, and clinical workflows


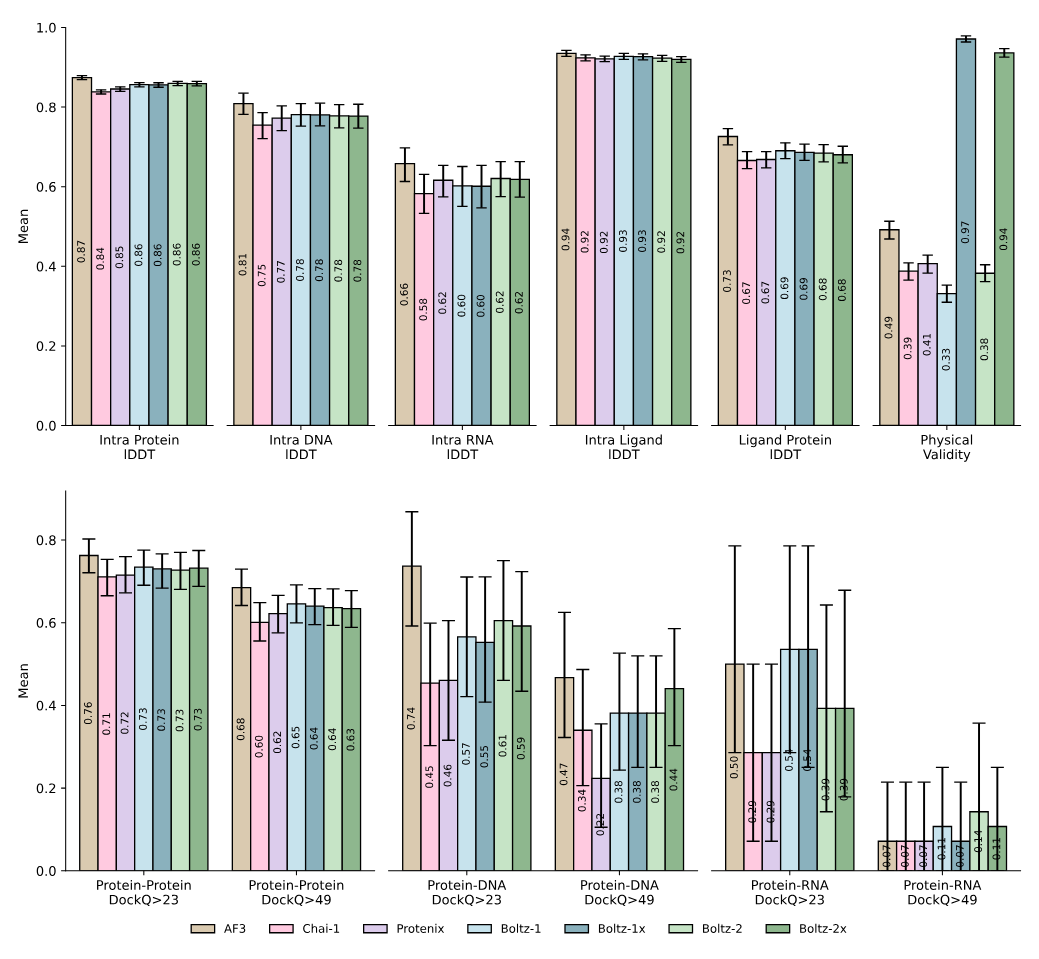
The latest addition arrived yesterday: Boltz-2, an open-source model from MIT and Recursion, jointly predicts 3D molecular structure and binding affinity—two core tasks in drug discovery—at speeds reportedly 1000x faster than traditional physics-based methods like FEP. It builds on AlphaFold3 and Boltz-1, but adds affinity modeling, controllable inference, and improved physical realism (via a technique called “Botz-Steering”, we wrote about Boltz-1 in April).
It’s a good moment to take another look at how the space has diversified since our last overview a few months ago. One way to track that is through deal flow. Since our March scan, biopharma has leaned even harder into AI-native platforms (many anchored in foundation models) and the pattern shows up clearly in the headline agreements struck over the past year up until now.
Among several recent agreements to exemplify this (reviewed in great detail by Andrew Marshall in a recent Nature Biopharma Dealmakers piece): in June 2024, Merck KGaA paid tens of millions of euros upfront (plus €346M in potential milestones) to access Biolojic Design’s AI-created antibodies; GSK spent $37.5M on Ochre Bio’s specialized single-cell liver data; Novartis committed $65M upfront to Generate:Biomedicines' generative protein platform, and Eli Lilly invested $13M upfront in Creyon Bio’s RNA-based therapies. AstraZeneca topped these with a $200M oncology-focused deal with Pathos AI and Tempus, to leverage multimodal patient data from more than 150,000 people, making AI core to its discovery pipeline.
Brief general recap: Foundation models (2021) are large AI systems trained on massive, unlabeled datasets to recognize patterns and predict missing pieces (like the next word in a sentence or a masked part of an image). Instead of relying on labeled examples, they use self-supervised learning, adjusting millions or billions of parameters to reduce prediction errors across iterations. Most use the transformer architecture, which includes a self-attention mechanism that lets the model assess how each word (or image patch) relates to all others in the input—capturing full context regardless of order.
Rather than building new models for each use case, developers fine-tune or prompt a single pretrained system. Early examples include BERT (2018), GPT (2018–), PaLM (2022), and DALL·E 2 (2022). Many newer models support multimodal inputs like text, images, and speech.
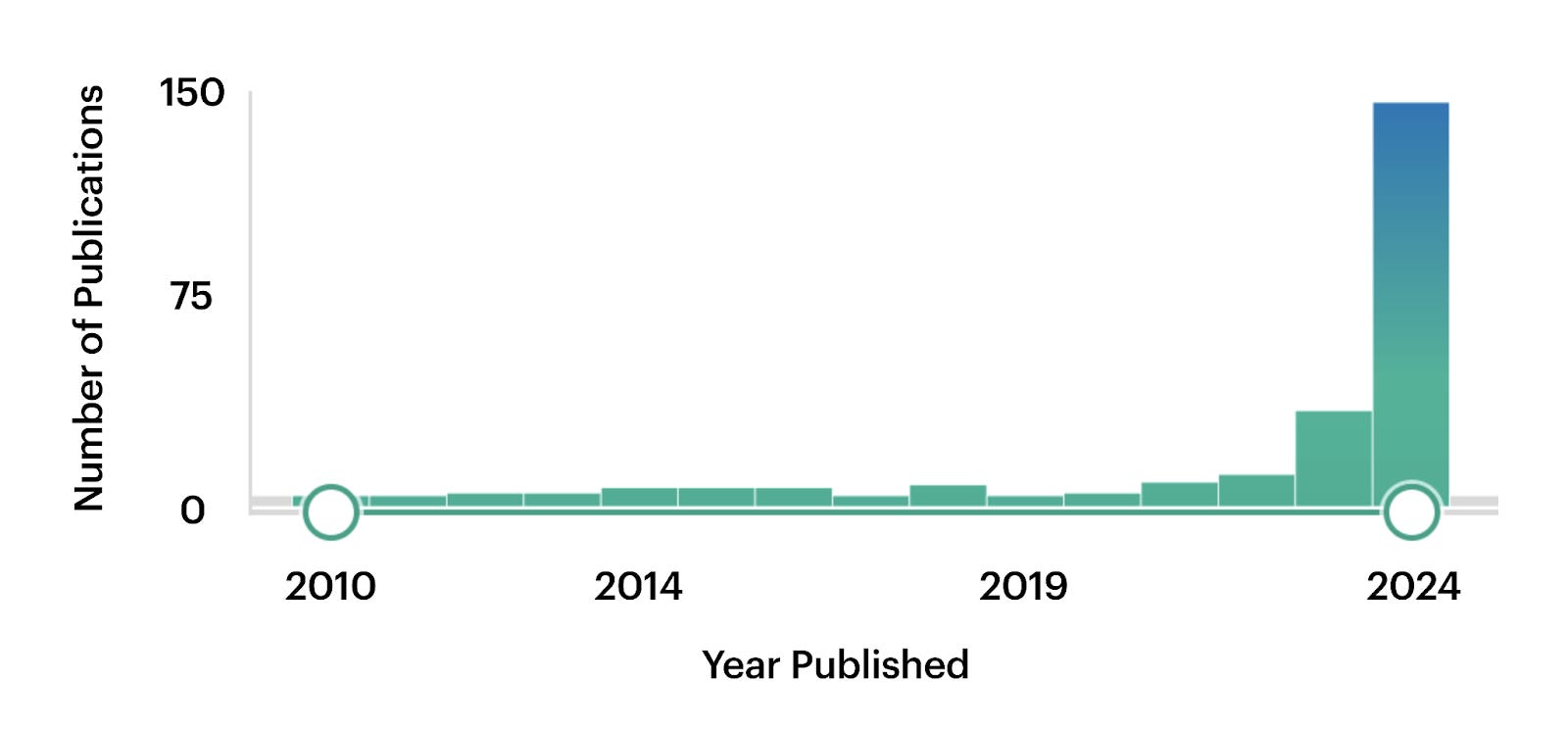
Per the recap, in biology this means combining diverse datasets (e.g. genes, proteins, chromatin) into unified frameworks, which may open new research directions. PubMed trends speak so: before 2023, mentions of “foundation model” barely hit 10 per year, then surged to around 150 by 2024.
Historically, drug researchers have focused narrowly on one target at a time (usually a single protein) treating it as an isolated problem and going step-by-step: forming hypotheses, validating targets, screening compounds, optimizing leads, and running clinical trials, each step typically consuming considerable time and resources.
Today, FMs facilitate a more holistic view of biological systems. Key shifts enabled by this technology include:
Multi-Omics Integration: FMs combine diverse biological data types (genomic, transcriptomic, proteomic, metabolomic) to gain deeper understanding of complex diseases such as cancer or neurodegenerative disorders. For example, Deep Genomics uses AI to identify RNA-based therapies by analyzing genetic mutations affecting RNA splicing.
Data-Driven Target Discovery: FMs can uncover novel therapeutic targets by analyzing large datasets without pre-defined hypotheses.
Multi-Target Strategies: These models facilitate polypharmacology, targeting multiple biological pathways simultaneously, essential for treating complex diseases like cancer and Alzheimer's.
Generative Models for Drug Design: Generative AI models (e.g. Insilico Medicine’s Chemistry42) create novel molecules optimized to interact effectively with multiple targets within biological systems.
Personalized Medicine: By incorporating individual genetic and medical histories, FMs may predict therapy responses, enabling personalized treatments (companies like Bioptimus use multi-omics data to forecast drug efficacy and customize treatment plans).
Reduction in Experimental Burden: FMs may greatly reduce early-stage experimental requirements by virtually predicting drug interactions, toxicity, and pharmacokinetics. Platforms like NVIDIA’s BioNeMo, or DiffDock allow researchers to efficiently screen many drug candidates in virtual settings before lab-based testing.
Now, to the recent model arrivals from the industry and academia.