
Addressing Data Bottlenecks in the Era of AI-driven Drug Discovery
There is an important component of drug discovery "industrialization" which is still largely missing. Thanksfully, a group of companies are bringing about the needed change.

This week’s Where Tech Meets Bio is sponsored by Syntekabio (KOSDAQ: 226330), a South Korean leader in AI-driven drug discovery.
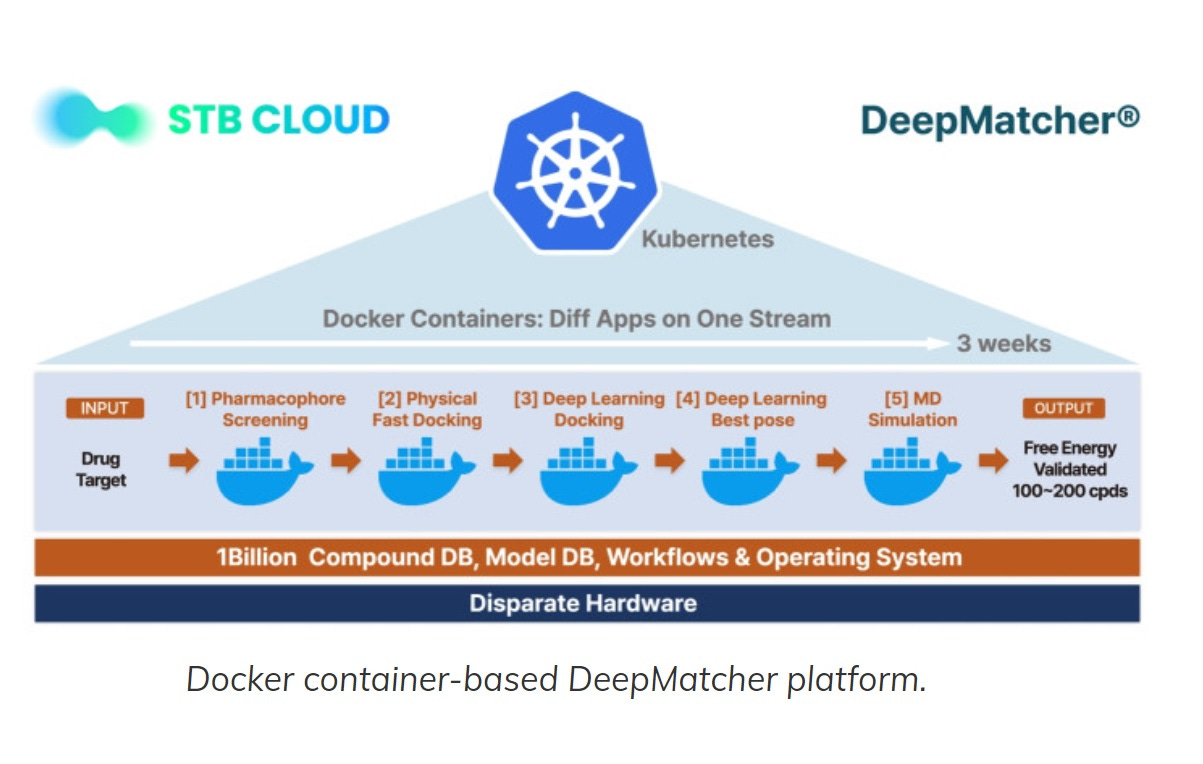
Syntekabio's STB CLOUD is a fully automated, cloud-based AI platform aimed at accelerating early-stage drug development. Traditionally, this process takes five years or more, but with STB CLOUD, developers can reach the pre-cli…